- Published on
Consensus Algorithms Through the Eyes of an Infosec Architect
- Authors

- Name
- Ted
- @supasaf
We’ve recently been evaluating some vendors for secrets management solutions. Due to some unfortunate legal or market reasons, well-known products like Akeyless can’t be sold in our local market. That pushed us to look into alternative solutions.
Now, secrets management demands extremely high availability (HA). I mean, nobody wants to wake up at 3 a.m. because the system storing your passwords decided to take a nap. So I spent some time analyzing how different vendors implement HA.
Some vendors use a primary-standby model based on traditional databases like PostgreSQL. Others go fancier and adopt consensus algorithms like Raft.
Yesterday, a teammate asked:
“What exactly is a consensus algorithm?”
That question hit me right in the brainstem.
I once worked for a company with a product that had over a billion DAUs. Under the hood, it used a Paxos-based system called paxosstore. The core logic? Less than 2,000 lines of C++. Nowadays, I have to admit — I can barely read that C++ anymore. But I thought — why not write a tiny version of Raft myself in Go? Just for fun and to sharpen my understanding of the secret manager tech we’re reviewing.
Disclaimer: My little Raft only does leader election, failure recovery, and node restarts. It’s not ready for production or serious use. If you want a deep dive into a more solid Go implementation, check out this excellent series.
TL;DR
- I wrote a Raft mini-clone in Go
- It fits in a single file
- It does elections and heartbeats
- It doesn’t do log replication (yet)
- But hey — it was fun!
What Does This Raft Do?
Just the basics:
- Leader election
- Heartbeats
- Failover (when leader dies, a new one is elected)
- REST API for testing
Each node is just an HTTP server. They ping each other, vote for leaders, and complain when they don’t get love from others (i.e. no heartbeats).
How Does It Work?
You start each node in a separate terminal:
# Terminal 1
go run main.go 0
# Terminal 2
go run main.go 1
# Terminal 3
go run main.go 2
Meanwhile, I had a little monitoring shell script running to watch the cluster:
$ ./test.sh monitor
=== Raft Cluster Status Monitor ===
=== Checking status of all nodes ===
Node on port 8081:
Node on port 8082:
Node on port 8083:
=== Finding the Leader node ===
No leader found.
Soon after starting, you’ll see something like:
Node on port 8081:
{
"id": 0,
"state": "Leader",
"current_term": 15,
...
}
Node on port 8082:
"state": "Follower"
Node on port 8083:
"state": "Follower"
=== Leader found on port 8081 ===
Yay, it elected a leader!
Kill the Leader (for Science)
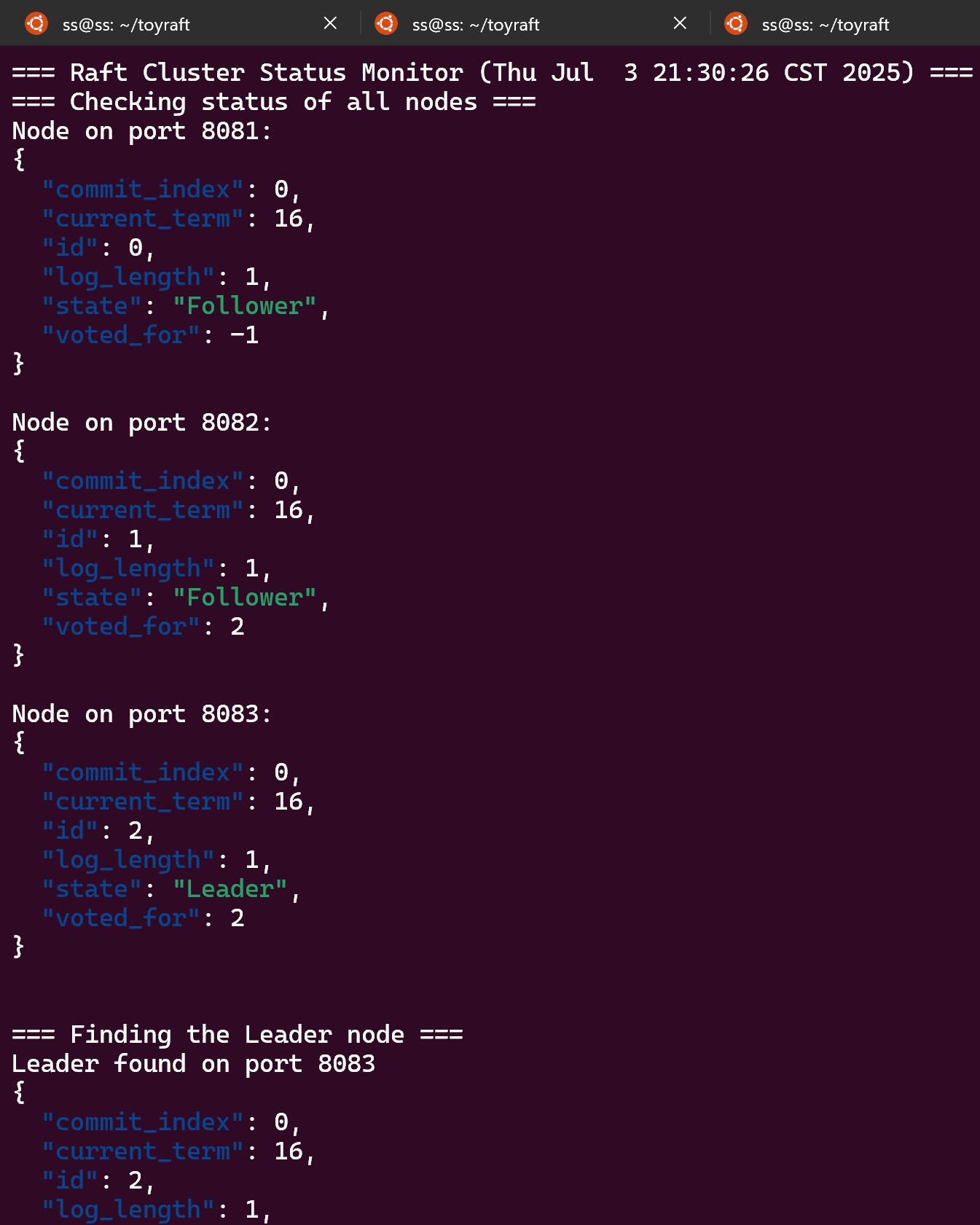
When I Ctrl+C the leader process (port 8081), the cluster recovers:
Node on port 8082:
"state": "Follower",
"voted_for": 2,
"current_term": 16
Node on port 8083:
"state": "Leader",
"voted_for": 2,
"current_term": 16
=== Leader found on port 8083 ===
Later, if I restart the killed node (go run main.go 0), it happily rejoins the cluster.
Code Highlights (Without Making Your Eyes Bleed)
The Basic Architecture
Our implementation models each server as a RaftNode that can be in one of three states:
// NodeState represents the state of a node in the Raft cluster.
type NodeState int
const (
Follower NodeState = iota
Candidate
Leader
)
- Follower: The default state. Followers respond to requests from leaders and candidates
- Candidate: A node trying to become leader during an election
- Leader: The node that handles all client requests and coordinates log replication
Core Data Structures
Each Raft node maintains several key pieces of state:
// RaftNode represents a single node in the Raft cluster.
type RaftNode struct {
id int // The unique ID for this node.
peers []string // The network addresses of the other nodes in the cluster.
state NodeState // The current state of the node (Follower, Candidate, or Leader).
currentTerm int // The latest term the server has seen.
votedFor int // The candidateId that received a vote in the current term (-1 if none).
log []LogEntry // The log entries; the first entry is a sentinel.
commitIndex int // The index of the highest log entry known to be committed.
// ... other fields
}
The currentTerm is crucial - it's like a logical clock that helps nodes understand the sequence of events in the cluster.
Leader Election
When a follower doesn't hear from a leader for a certain time, it becomes a candidate and starts an election:
func (rn *RaftNode) runElection() {
rn.currentTerm++ // Increment term
rn.votedFor = rn.id // Vote for ourselves
term := rn.currentTerm
// ... unlock and prepare request
votes := make(chan bool, len(rn.peers))
votes <- true // Vote for self.
// Send vote requests to all peers concurrently.
var wg sync.WaitGroup
for _, peer := range rn.peers {
wg.Add(1)
go func(peerAddr string) {
// ...
if resp, err := rn.sendVoteRequest(ctx, peerAddr, req); err == nil {
select {
case votes <- resp.VoteGranted:
case <-ctx.Done():
return // Context timed out or was cancelled.
}
rn.mu.Lock()
// If a response contains a higher term, step down and become a follower.
if resp.Term > rn.currentTerm {
rn.currentTerm = resp.Term
rn.state = Follower
rn.votedFor = -1
rn.resetElectionTimer()
}
rn.mu.Unlock()
}
}(peer)
}
// Tally the votes.
voteCount := 0
for vote := range votes {
if vote {
voteCount++
}
}
// Check if we got majority votes
majority := len(rn.peers)/2 + 1
if voteCount >= majority && rn.state == Candidate && rn.currentTerm == term {
log.Printf("Node %d became leader for term %d with %d votes", rn.id, rn.currentTerm, voteCount)
rn.state = Leader
rn.initLeaderState()
// Stop the election timer as a leader.
if rn.electionTimer != nil {
rn.electionTimer.Stop()
}
}
}
The election process is straightforward:
- Increment the current term
- Vote for yourself
- Send vote requests to all other nodes
- If you get a majority of votes, become leader
Handling Vote Requests
When a node receives a vote request, it follows these rules:
func (rn *RaftNode) handleVote(w http.ResponseWriter, r *http.Request) {
// ... parse request
resp := VoteResponse{
Term: rn.currentTerm,
VoteGranted: false,
}
// Update term if candidate has higher term
if req.Term > rn.currentTerm {
rn.currentTerm = req.Term
rn.state = Follower
rn.votedFor = -1
}
// Grant vote if conditions are met
if req.Term == rn.currentTerm && (rn.votedFor == -1 || rn.votedFor == req.CandidateID) {
lastLogIndex := len(rn.log) - 1
lastLogTerm := 0
if lastLogIndex > 0 {
lastLogTerm = rn.log[lastLogIndex].Term
}
// ... send response
}
A node will vote for a candidate if:
- The candidate's term is at least as high as the node's current term
- The node hasn't already voted for someone else in this term
- The candidate's log is at least as up-to-date as the node's log
Heartbeats and Log Replication
Once elected, a leader must send regular heartbeats to maintain its authority:
func (rn *RaftNode) sendHeartbeats() {
// ... prepare heartbeat request
for i, peer := range rn.peers {
req := AppendRequest{
Term: term,
LeaderID: rn.id,
PrevLogIndex: prevLogIndex,
PrevLogTerm: prevLogTerm,
Entries: []LogEntry{}, // Empty for heartbeats.
LeaderCommit: leaderCommit,
}
if resp, err := rn.sendAppendRequest(ctx, peerAddr, req); err == nil {
// Handle response
if resp.Term > rn.currentTerm {
// Step down if we discover higher term
rn.currentTerm = resp.Term
rn.state = Follower
rn.votedFor = -1
rn.resetElectionTimer()
}
}
}(peer, i)
}
}
Heartbeats serve two purposes:
- They prevent followers from starting elections
- They're the same mechanism used for replicating log entries
The Main Loop
Each node runs a simple state machine:
func (rn *RaftNode) run() {
for {
// Perform actions based on the current state.
switch state {
case Candidate:
go rn.runElection()
case Leader:
go rn.sendHeartbeats()
}
}
}
}
This loop ensures that:
- Followers wait for messages from leaders(NO
casebranch inswitch state) - Candidates run elections when their timer expires
- Leaders send regular heartbeats
Election Timeouts
A critical part of Raft is the election timeout - how long a follower waits before becoming a candidate:
func (rn *RaftNode) resetElectionTimer() {
if rn.electionTimer != nil {
rn.electionTimer.Stop()
}
// Use a randomized timeout between 800ms and 1200ms.
timeout := time.Duration(800+rand.Intn(400)) * time.Millisecond
rn.electionTimer = time.AfterFunc(timeout, func() {
rn.mu.Lock()
// Only start an election if not already a leader.
if rn.state != Leader {
log.Printf("Node %d election timer expired, becoming candidate.", rn.id)
rn.state = Candidate
}
rn.mu.Unlock()
})
}
The randomization is important - it prevents multiple nodes from becoming candidates at the same time, which would split the vote.
What's Missing
This implementation is simplified and missing several important features:
- Log Compaction: In a real system, logs can't grow forever
- Persistent State: Nodes should survive restarts
- Client Interface: There's no way for clients to submit operations
- Membership Changes: Can't add or remove nodes from the cluster
What I Learned
This hands-on Raft experiment gave me a much better mental model of how HA works under the hood for products like open-source version of something.
More importantly, I understood why Raft hates long-distance relationships. Raft was designed for low-latency networks — like machines within the same data center or cloud region.
If you try to stretch a Raft cluster across regions (e.g., Region A, B, and C), the latency will kill it. Seriously.
You’ll run into:
- ❌ Frequent leader elections (due to timeouts)
- ❌ Awful write performance (consensus needs roundtrips)
- ❌ Split-brain risks (everyone thinks they’re the leader 😵)
So unless you’re operating within a tightly-knit region (like us in Region A), don't stretch Raft too far. It gets grumpy.
What If You Can’t Afford Enterprise?
That brings me to the real question:
“What if the enterprise version (which supports multi-region HA) isn’t approved for procurement?”
I don't have a perfect answer just yet; I'm still evaluating the trade-offs and expect to build some custom code to help reduce the risks. Perhaps I'll have the opportunity to share more on this in the future.